
It’s a big problem because it’s intertwined with other concepts like change detection or asynchronous programming.
The solution that Angular provided to those two were the following:
- Zone.js – detecting any changes and trigger the change detection to the whole tree of nodes
- RxJS – a library for reactive programming using observables that makes it easier to compose asynchronous or callback-based code.
Both of them are hard to work if you’re not experienced enough. You might say that reactivity is not something that you can grasp easily for a concept that is crucial in a modern web application.
The problems that I had so far with RxJS were the following:
- I still find debugging Observables annoying due to their asynchronous behaviour.
- Unit testing setup can be a pain sometimes, especially if you have a more complex logic involving observables. If you work on some legacy code where someone who thought that having a 3k+ lines of code component is a good idea, you know what I’m talking about.
Now let’s see if and how signals make our life easier.
Signals
Angular 16 added a new feature called Signals. It’s a new feature for Angular but not for the frontend world. It’s not a new concept in the UI development stage. The first reference that I could find was in C++ together with Qt 5 back in 2013. The old is new.
Nowadays, signals were introduced in SolidJS and I think their definition encapsulates its power:
“Signals are the cornerstone of reactivity in Solid. They contain values that change over time; when you change a signal’s value, it automatically updates anything that uses it.” – SolidJS – Introduction to Signals
Angular’s definition is a bit more technical but almost on the same page:
“A signal is a wrapper around a value that can notify interested consumers when that value changes” – Angular’s Guide to Signals
Signals vs Observables
The first time I read this definition, I was sure they were talking about Observables.
In my head, the equation was simple.
A value that changes over time = Stream of data = Observable.
But it wasn’t the case.
It resembles some functionality but behind the scenes, some differences fundamentally change the way we think about values.
One example that convinced me to further research this subject was a simple one.

I can’t get the value out of an observable without having to subscribe to it. You can’t access it all the time. And that’s the biggest difference – Time.
Signals don’t understand time. Is just a wrapper on a value. You can access that wrapper whenever you want.
Another important aspect of it is when you read or write values to signals, you do it through methods that notify other signals that use that change signal.
It’s the same pattern of producer/consumer but without time. That’s pretty cool!
How do I use them?
Signals are straightforward to use and they accept any type of data from primitives to objects.

To use angular signals in the template you will have to call the method in the template

This is probably one of the most controversial aspects of signals. To access it you will have to call a method inside the template which is a big smelly no-go.
Calling methods inside the template is bad due to recalculations. Angular doesn’t know what value will be at the end of execution.
In the case of signals, this aspect is covered by using the memoization technique, which means that the value of the function will be cached and will not be recalculated only if needed.
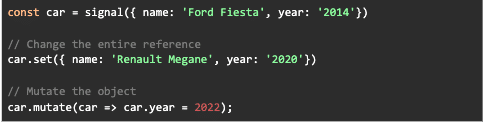
Writable Signals
These are signals that can have their values modified through set() , update() or mutate()
- We use set() when we want to change the reference of what’s inside the signal and notify other signals of the change.
- We use update() when we want to change the reference based on the previous value.
- We use mutate() when we want to change part object and notify other signals that use this signal to react to the new changes. Mutate works great with data structures like Arrays or Sets where you want to change the values without changing the references
Read-only or Computed Signals
These are signals that use other signals to change their values. It’s read-only because they can be changed only if they are notified that any signal that they use is changed.
Therefore, we don’t have set(), update() or mutate()
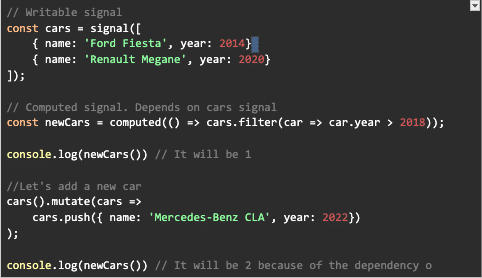
Dependency Graph
We can see that all of those recalculations are done automatically. But how does it work?
This time, we will take a look at Signals implementation. You can find it in the repo of Angular. I always recommend diving inside the repo if you don’t understand a subject. That’s the only source of truth that you have at the end of the day
If we take a look inside the graph.ts we will see a declaration of this

Producers and consumers are part of ReactiveNode abstract class, a class that is implemented by WritableSignalsImpl and ComputedImpl.
Updating the producers and consumers is done through the method producerAccessed part of ReactiveNode . You can see that there’s also trackingVersions and valueVersions which are used to determine if the edge in the graph is stale or not.

Once you access it, it automatically adds the calling signal to the consumer’s list.
How does it get notified?
Pretty easy, if you use set or update methods, you will see inside of them the following line. You can find it in the graph.ts
this.producerMayHaveChanged();
This method will traverse all the consumers, see which ones are still relevant and notify the signals to recalculate themselves.
How do we visualise this? We can determine the graph by just drawing it.
Let’s say we have a signal called parkingLot and another two computed signals isParkingFree and isElectricParkingFree.

Each time we will set or mutate the value of parkingLot, isParkingFree and isElectricParkingFree will be recalculated and rendered to the UI as sync values. You will don’t have to manually do the calculations because they will be done on a change
The dependency graph will look something like this:
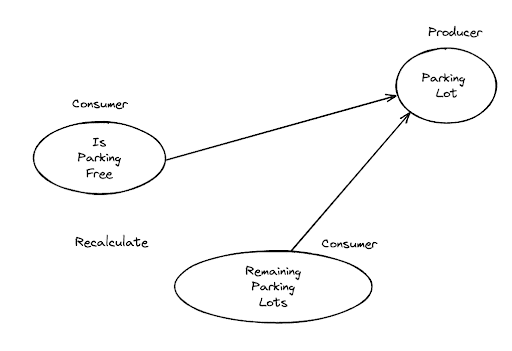
You can find the link to the parking lot example here
Trade-offs
Every new piece of technology comes with trade-offs, no matter how good and shiny it is.
Pro
- This transition to signals will be a new beginning for Angular’s reactivity concepts. I have to say that for a new developer that comes to Angular will be way easier to understand reactivity without having to understand all the underlying details of change detection and changing to OnPush change detection or zones.
- Observables will still be a thing in Angular but the interop between signals and them is amazing.
- An easier mental model than observables and asynchronous computations. Signals are always synchronous because they always have a value. This might come in handy for new developers.
- Fine-grained reactivity.
Cons
- It’s still a new concept in Angular so expect changes.
- A new mental model for experienced developers who are already familiar with RxJS.
- Decision fatigue – when do I use Observables and when do I use Signals?
Conclusions
Signals are a very brave step forward from Angular’s team to a more fine-grained reactivity. We’ve seen what a big change is when you give up on the concept of time and move from a more asynchronous approach to a synchronous one.
It is a feature that I’m very curious about and I want to see how it’s going to resist the test of time and if it will have traction.
If you want to study more on this subject. I recommend these articles.

